

Le dark web est difficile à surveiller. En plus d'être structurellement difficile à naviguer, les acteurs malveillants ont un vocabulaire unique qui est complexe à comprendre pour les étrangers.
Le web scraping et le web crawling permettent d'extraire et d'indexer des informations à plus grande échelle. Ces outils ont besoin de règles écrites manuellement pour fonctionner. Étant donné que ces processus nécessitent des opérateurs humains pour écrire et maintenir les configurations de grattage Web, cela limite le nombre de sites Web pouvant être surveillés.
Pour surveiller automatiquement, et donc plus efficacement, le dark web, l'application du traitement du langage naturel (NLP) aux renseignements sur les cybermenaces peut être efficace.
Avec NLP, Flare a pu :
- Analysez les interactions entre les acteurs de la menace avec le premier tokenizer adapté au dark web, le Tokenizer Web sombre
- Automatisez le processus de scraping Web avec le extracteur automatique, Kyber, qui est capable d'extraire les titres, la date de publication et les auteurs d'une variété de forums illicites, sans avoir besoin d'assistance humaine
- Regroupez les acteurs malveillants pour mieux comprendre les risques de menace avec le Modèle d'acteur similaire
Flare surveille le dark web depuis 2017 et, au début de 2022, a enregistré près de 3 profils de forum uniques, plus de 1.6 million de sujets de discussion sur le forum et près de 1.9 million de listes de dark web !
Notre expert en IA Olivier Michaud et responsable des données/IA François Masson a parlé Tokéniser le Dark Web : appliquer la PNL dans le contexte de la cyberveille sur les menaces au SECTEUR. Avez-vous manqué la conversation? Ne vous inquiétez pas, nous discuterons de leur présentation ci-dessous.
Qu'est-ce que le traitement automatique du langage naturel (TLN) ?
La PNL est un domaine de l'Intelligence Artificielle (IA) qui concerne les ordinateurs "comprenant" le langage humain. Diverses technologies se combinent pour que les ordinateurs puissent prendre des données textuelles ou vocales et produire une réponse qui reflète les intentions de l'auteur/locuteur d'origine. Ses applications pratiques incluent la détection de spam, la traduction et l'analyse des sentiments. Il reste de nombreuses questions à explorer car il s'agit d'un domaine de recherche actif.
Les humains ont des capacités uniques pour interpréter les nuances et les différents styles d'écriture/d'expression, ce qui est compliqué à apprendre aux ordinateurs à déterminer avec précision.
Quel est le défi de l'analyse des informations provenant de sources illicites ?
Il y a trop de points de données et de sources pour qu'une équipe de cybersécurité puisse bien surveiller tous les contenus illicites.
Il y a plusieurs raisons pour lesquelles le dark web demande des efforts pour naviguer et analyser :
- Il évolue rapidement et possède sa propre culture unique
- Les langues les plus parlées sont de loin l'anglais et le russe, mais il existe d'autres langues dont le français, le polonais et le vietnamien, l'analyse doit donc être multilingue
- Il y a du jargon et du jargon lié à la fraude
- Il y a des mots mal orthographiés et des emojis
- Les acteurs malveillants ont des noms d'utilisateur uniques (notre point de vue est que l'outil ne devrait pas apprendre chaque nom d'utilisateur, mais plutôt qu'un nom d'utilisateur est composé de lettres, de chiffres, etc.)
- Dans certaines situations, le style d'écriture est important, donc le nettoyage du texte peut entraîner la perte d'informations pertinentes (par exemple, un acteur peut utiliser des points d'interrogation plus que d'autres)
Comment la PNL peut-elle être appliquée au Dark Web ?
Les outils PNL disponibles surveillent principalement le contenu de Wikipédia et sont construits autour de la compréhension d'un anglais "propre" sans jargon, mots mal orthographiés et symboles/émojis. Il existe des outils écrits par des personnes pour analyser les informations provenant de sources illicites, mais ils ne sont pas automatiques. De plus, il n'y a pas beaucoup de recherches dans ce domaine car les données provenant du dark web sont rares.
Flare surveille et documente le dark web depuis 2017, et notre équipe d'intelligence artificielle crée des outils pour analyser le nombre croissant d'acteurs malveillants et leurs activités sur la plateforme.
L'expert en IA de Flare, Olivier Michaud, a collaboré avec Flare pour son projet de mémoire de maîtrise en IA à l'École de technologie supérieure. Le sien projet de recherche a enquêté sur l'automatisation de l'extraction de données à partir de divers forums Web sombres à l'aide de la PNL, et les outils Kyber et Similar Actor Model de Flare découlent de ses idées.
Comment parler "acteur malveillant"
La formation d'un modèle à l'aide du traitement du langage naturel (TAL) est un défi. En former un adapté au vocabulaire unique des acteurs malveillants devient encore plus difficile.
Il y a quelques étapes à accomplir pour entraîner un ordinateur à comprendre le langage des acteurs malveillants :
1. Créer un nouveau lexique
L'anglophone natif typique de 20 ans connaît environ 40,000 XNUMX mots, et en utilise activement 20,000 XNUMX. Il existe des milliers d'autres mots, sans compter les mots mal orthographiés, les variations de mots et l'argot.
Nous ne voulions pas que notre vocabulaire soit trop large, car le modèle ne peut pas apprendre tous les mots, mais il ne peut pas être trop petit, car il n'y aura pas assez d'informations à partir desquelles apprendre. Trouver un équilibre entre ceux-ci permet au modèle d'apprendre suffisamment de mots pour les analyser efficacement.
2. Construire le Tokenizer
L'application de la PNL consiste à transformer des phrases en unités plus petites appelées jetons, qui peuvent être représentées sous forme de texte ou de nombres, et alimentent le modèle. Ce processus est la tokenisation.
Il existe de nombreuses façons de tokeniser, mais ici nous avons choisi l'algorithme de codage par paire d'octets (BPE). Avec BPE, les mots peu courants sont divisés en sous-mots pour réduire la taille du vocabulaire, tandis que les mots courants sont conservés intacts. Ainsi, le mot "hacking" peut être divisé en "hack" et "ing".
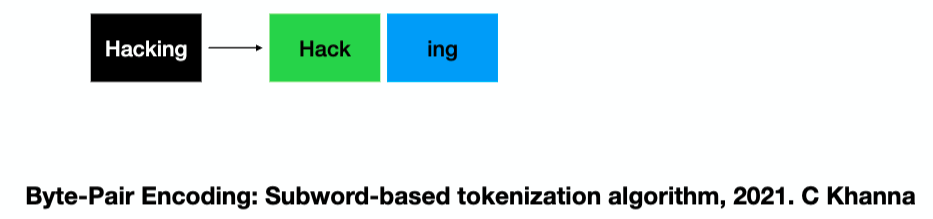
Sennrich, R., Haddow, B. & Birch, A. (2016). Traduction automatique neuronale de mots rares avec des unités de sous-mots. Actes de la 54e réunion annuelle de l'Association for Computational Linguistics (Volume 1: Long Papers), pp. 1715–1725. doi : 10.18653/v1/P16-1162.
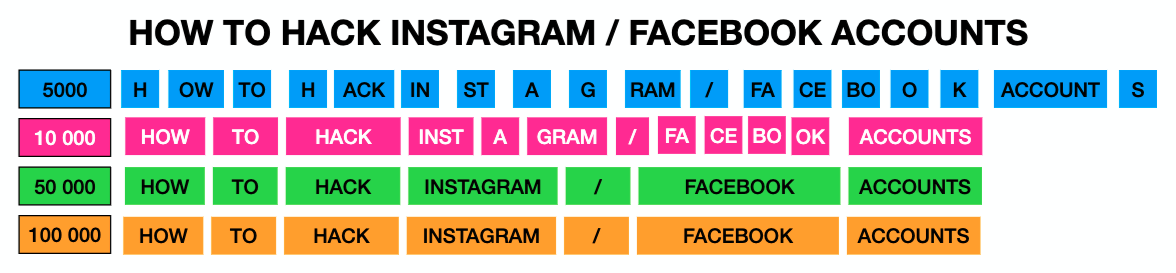
Ce tokenizer a été formé par l'équipe Flare AI text provenant de 29 sources illicites dans différentes langues au cours de plusieurs années, avec plusieurs tailles de vocabulaire : 5,000 10,000 ; 50,000 100,000 ; XNUMX XNUMX ; et XNUMX XNUMX.
À mesure que la taille du vocabulaire augmente, le nombre de jetons diminue. À 5,000 100,000 mots, le tokenizer divise la plupart des mots en sous-mots, tandis qu'à XNUMX XNUMX mots, le tokenizer conserve la plupart des mots intacts.
Il s'agit du premier tokenizer open source formé avec une base de données contenant des années de contenu provenant d'interactions sur le dark web. Cette le tokenizer est disponible sur GitHub.
Extraction automatique de contenu de forums illicites
La surveillance et l'extraction de données à partir de sources illicites (également appelées scraping Web) nécessitaient auparavant la création de règles HTML/CSS écrites manuellement pour chaque page Web. Certains défis incluent :
- Les sites Web évoluent constamment, de sorte que les outils conçus pour les gratter doivent également changer
- Les forums ont des styles et des structures HTML différents, donc une règle qui fonctionne pour l'un peut ne pas l'être pour l'autre
- Il n'y a pas d'ensemble de données public disponible
- Le bavardage des acteurs de la menace peut être déroutant
Avec l'étiquetage séquentiel, les cyber-équipes peuvent extraire des pages Web de manière proactive en enseignant à l'outil certaines associations de mots. Par exemple, dans cette phrase sur Star Wars, certains mots ont des catégories associées.

Avec la outil d'extraction automatique Kyber, le modèle entraîné peut lire des pages HTML et générer des données structurées. Kyber peut :
- S'adapter aux modifications HTML des pages Web au fil du temps : les sites Web évoluent constamment et les règles HTML/CSS écrites manuellement fonctionnent lorsque leur code correspond au code de la page Web, tandis que Kyber est plus flexible.
- Travailler sur plusieurs sources : Kyber surveille diverses communautés illicites.
- Fonctionne sans intervention humaine : Kyber est le premier outil à analyser automatiquement les interactions du dark web, alors que d'autres outils existants nécessitent des règles écrites manuellement.
- Bonne performance : après avoir analysé 10 titres de pages Web sombres avec l'ancienne méthode d'écriture manuelle du code HTML/CSS pour chaque page, Kyber était précis à 90 % dans la détection des titres.

Une autre application de la PNL au Dark Web : modèle d'acteur similaire
Kyber n'est pas le seul outil basé sur la PNL qui analyse le dark web. Le modèle d'acteur similaire applique également le NLP aux sources illicites et s'appuie sur le tokenizer, qui peut avoir plusieurs applications.
Cet outil identifie les similitudes entre les acteurs de la menace afin que nous puissions regrouper les acteurs similaires en fonction du contenu qu'ils ont publié.
Les avantages de l'identification d'acteurs similaires incluent :
- Détection d'un changement de nom d'utilisateur pour un auteur de menace
- Identifier les menaces potentielles avant toute action malveillante
- Fournir des informations précieuses pour déterminer le risque qu'un certain acteur pourrait représenter pour votre organisation
- Réduire le bruit rencontré dans les enquêtes en identifiant les acteurs de la menace Web sombre à faible risque
Des acteurs similaires écrivent un contenu similaire soit parce qu'il s'agit de la même personne avec un pseudonyme différent, soit parce qu'il s'agit de plusieurs acteurs travaillant pour la même organisation ou pour les mêmes intérêts.
Lisez plus de détails sur pourquoi, comment et les résultats du regroupement d'acteurs malveillants avec l'IA avec notre rapport, Regroupement d'acteurs malveillants : une histoire d'intelligence artificielle en trois parties.
Quel est l'avenir de cet outil ?
Il existe de nombreuses possibilités pour l'extracteur automatique. Actuellement, il se limite à extraire des informations des pages de sujets du forum.
L'extension des fonctionnalités de cet outil à l'avenir revient à appliquer ses capacités actuelles pour extraire des informations pertinentes telles que des secrets, des clés d'API, des entités, des relations entre les clés et les entités, etc.
Aussi, les plateformes de messagerie instantanée comme Telegram sont de plus en plus populaires auprès des acteurs de la menace. Les surveiller avec le modèle d'acteur similaire serait utile pour les équipes de cybersécurité.
Et grâce à la surveillance des plateformes de messagerie instantanée, une possibilité pour cet outil serait de faire le lien entre différentes communautés. Par exemple, il pourrait suivre un acteur menaçant qui est administrateur d'un forum Web sombre, qui en fait ensuite la promotion sur un chat de groupe de messagerie. Cela pourrait également être superposé à des informations géographiques pour étudier les relations entre des acteurs physiquement proches les uns des autres.
Comment Flare peut aider
La surveillance du dark web ne doit pas être écrasante. Flare vous permet d'analyser automatiquement le Web clair et sombre à la recherche des données divulguées de votre organisation, qu'il s'agisse de données techniques, de code source, d'informations d'identification divulguées ou de secrets sur les référentiels GitHub publics. Cette approche vous permet d'identifier de manière proactive les fuites de données sensibles et d'empêcher les violations de données avant que des acteurs malveillants ne les utilisent.
Flare vous permet, à vous et à votre équipe de sécurité, de :
- Anticipez la réaction aux tentatives d'intrusion sur le réseau avant qu'elles ne se produisent en détectant rapidement les informations d'identification volées et les appareils infectés à vendre
- Réduisez jusqu'à 95 % le temps de réponse aux incidents et surveillez environ 10 milliards d'informations d'identification divulguées
- Comprendre l'exposition des données externes de votre organisation (empreinte numérique) avec des recommandations proactives pour améliorer votre posture de sécurité en fonction de données contextuelles du monde réel
Vous voulez voir comment Flare peut surveiller les sources illicites pour votre organisation ? Demander une démonstration pour plus d'information.

