Anthropic Mythos represents a step change in cyber capabilities. Models have progressed from augmenting human analysts in vulnerability discovery and exploitation to autonomously discovering and writing exploits for zero-day vulnerabilities. This article is a primer for CISOs, security teams, and executives on risks posed by AI systems.
Key Takeaways About Anthropic Mythos and Cybersecurity
- Mythos represents a predictable continuation in model capabilities, and evidence indicates that it can execute an end-to-end successful takeover of a poorly defended network with minimal scaffolding.
- Currently there is no public reporting that indicates cybercriminals or hostile nation-state actors have access to Mythos or a Mythos level model, as a result we believe that the immediate risk to organizations is low.
- Within 6-18 months it is likely that an open-weight model will be available with Mythos level-capabilities that can be used to significantly automate cybercrime to include end to end attacks and vulnerability discovery and exploitation.
- Coverage of Mythos has largely been focused on automated zero-day vulnerability discovery and exploitation, but open-source AI with scaffolding is already accelerating identity based attacks, phishing, and other forms of social engineering.
- 2026 saw the first verified, large-scale, and successful cybercrime AI tools with the advent of Kali365 and EvilTokens.
- We recommend that organizations focus on collapsing the detection to response gap, leverage commercial AI pentesting and vulnerability detection tools, enhance monitoring of their attack surface, and increase investments in threat intelligence.
AI-Augmented Attackers Move in Minutes. Does Your Defense?
Flare delivers cyber threat intelligence, credential leak detection, and stealer log correlation: surfaced before they can be weaponized.
Anthropic Mythos and Project Glasswing
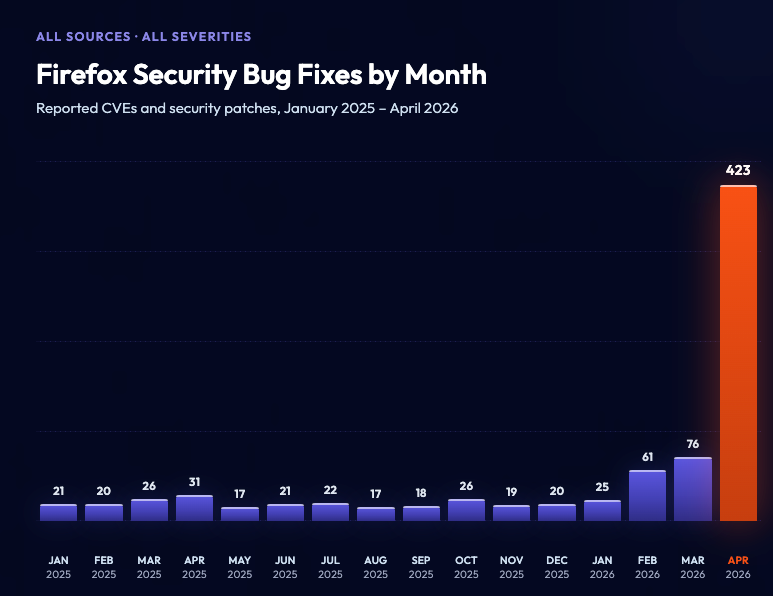
Mozilla Data on Firefox bug fixes by month, note the dramatic acceleration in 2026 (Mozilla is part of Project Glasswing)
Claude Mythos Preview was announced on April 7, 2026, alongside the launch of Project Glasswing, a project which provided Mythos access to a select set of companies to detect and patch zero-day vulnerabilities. It is also the first model to fully complete the AI Security Institutes cyber range end to end, meaning that in theory Mythos could autonomously fully take over a poorly defended network with a minimal scaffold (OpenAI’s ChatGPT5.5 has since been shown to also complete the same challenge).
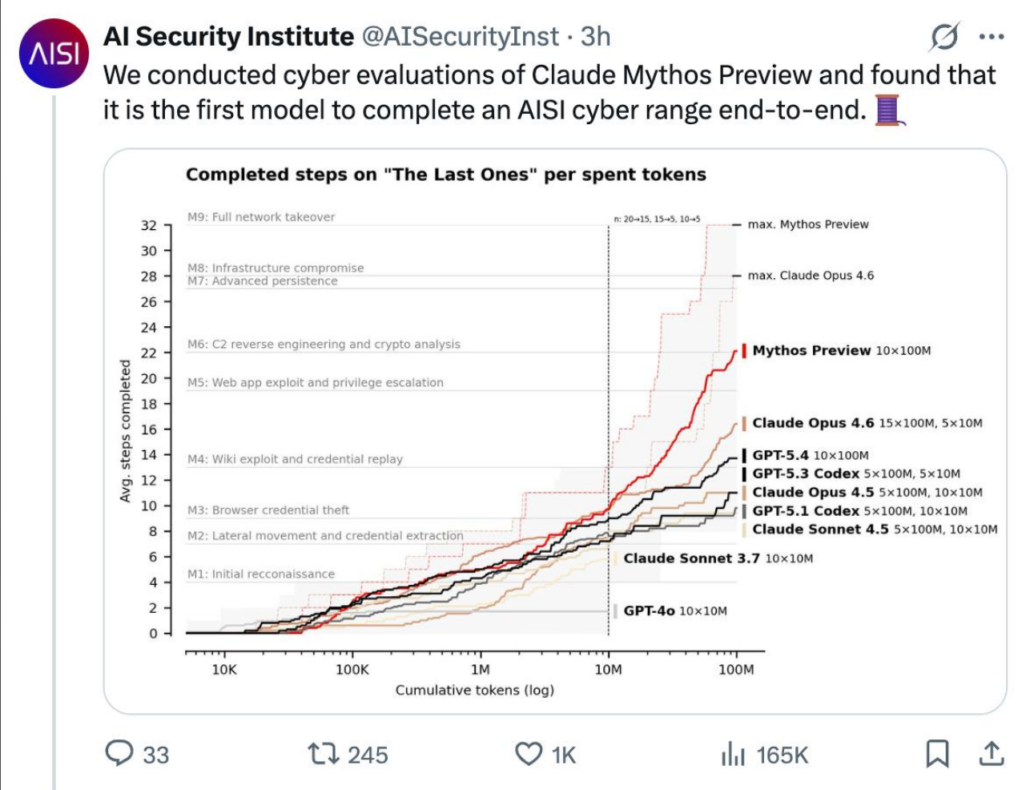
According to UK AISI, “The cap, alongside our use of a simple agent scaffold, artificially lowers success rates and understates what models can do with more tokens and stronger scaffolds. In return, it ensures time horizons are measurable and can be compared across models.“
We can see the same trend play out on METR’s evaluations for agentic software development, which is a good corollary for cybersecurity work.
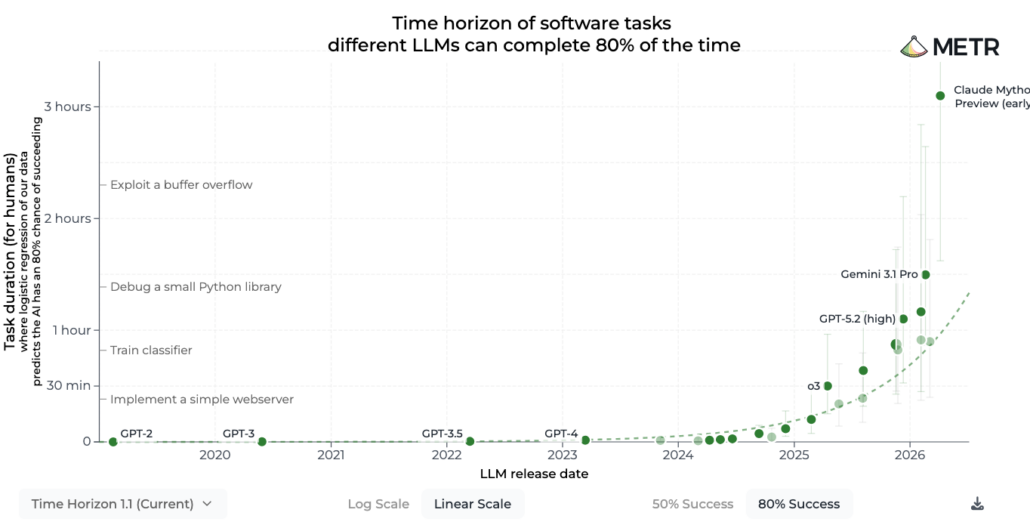
Claude Mythos achieved an 80% success rate on completing software development tasks that took the average developer three hours, and 16 hours when measuring based on a 50% success rate. We expect AI cyber capabilities to continue to increase at an exponential rate, with open-source models following roughly 6-18 months behind the current frontier.
Mythos and Cybersecurity Implications for Open-Weight Models
There is currently no known method to reliably ensure that open-weights models can’t be altered to produce harmful outputs. Mythos is currently not the danger itself, but a harbinger of a medium-term future in which a variety of sophisticated and unsophisticated cybercriminals will be able to leverage powerful AI without guardrails.
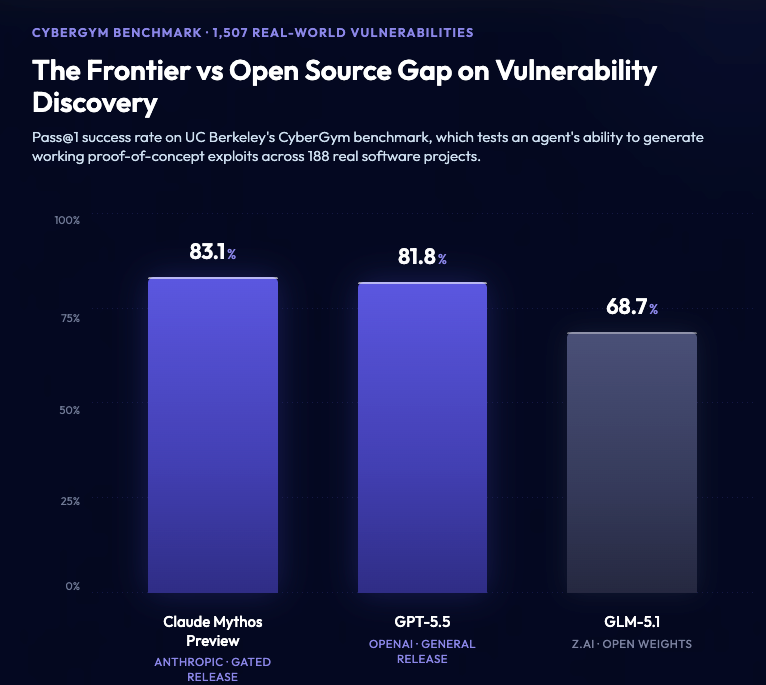
Z AI’s GLM-5.1 is significantly behind proprietary frontier models but is still valuable for vulnerability detection and exploitation
We categorize AI cyber risks in three primary buckets:
- AI for Social Engineering & Low-Level Automation: Threat actors are already heavily leveraging open-weight AI for cybercrime. For example both EvilTokens and Kali365 Panels were entirely vibe coded, and the phishing kits leverage AI to automate the creation of effective social engineering emails. We expect to see the use of AI in phishing, social engineering, and cybercrime tools to increase rapidly.
- AI for Vulnerability Discovery and Exploitation: Current open-source models are effective for discovering and exploiting known, documented vulnerabilities. We expect vulnerability discovery and exploitation to continue to increase as open-weight models continue to advance.
- Agentic AI for Cyberattacks: To date, we have seen nascent attempts by threat actors to build scaffolding for AI systems to autonomously launch cyberattacks, but they are currently bottlenecked by open-weight model capabilities. We expect these bottlenecks to dissolve over the next year as open-weight models reach the level of current frontier models.
This article will focus on understanding open-source models and their effect on cybercrime, which requires understanding two interdicting trends. First inference costs (what it costs to run an LLM) are dropping continuously and dramatically. Secondly, model capabilities are increasing exponentially with open-source models running 6-18 months behind proprietary frontier models.
To understand when we could reach a point where it would be cost effective for cybercriminals to use a future open-source Mythos level model we can plot Epoch AI’s inference compute cost compression against the known costs to run a Mythos level model.
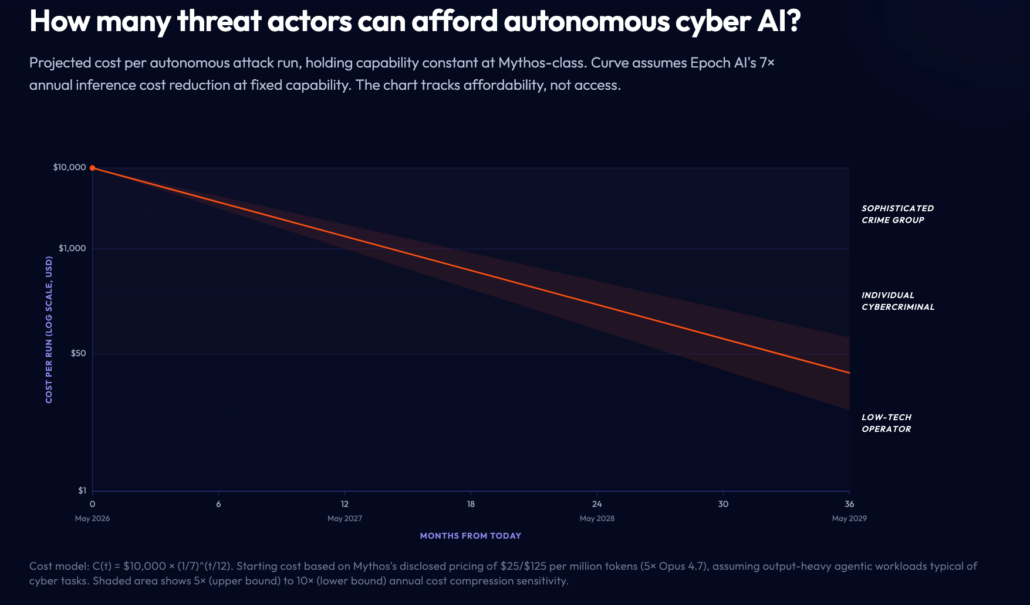
Depending on open-source model availability, this calculation results in the expectation of a model that can carry out end to end autonomous cyberattacks at an acceptable cost within 12-18 months of May 2026.
Recommendations for Security Teams in Different Realms of AI
Against AI-Augmented Social Engineering
- Move every user-facing authentication path to phishing-resistant credentials by the end of 2026. AI-generated phishing has decoupled lure quality from operator skill. The lures are good now and will be indistinguishable from legitimate correspondence within the year. The defensive answer is not better user training, it is authentication that cannot be relayed even when the user is fully convinced. This means hardware-bound credentials (FIDO2/WebAuthn with platform authenticators or security keys) for all employees, and synced passkeys for customer-facing flows where hardware keys are infeasible. Push notification MFA, SMS codes, and TOTP apps remain vulnerable to real-time phishing proxies (Evilginx, Modlishka, EvilTokens) and should be eliminated, not supplemented. The implementation pattern that works: enroll passkeys silently during normal logins for 60 days, then disable password fallback. Stop accepting MFA factors that can be intercepted, prompted, or relayed.
- Treat session tokens as a first-class identity surface and implement continuous session validation. EvilTokens does not phish passwords; it phishes OAuth device codes and steals session cookies. Every Microsoft 365, Google Workspace, and SaaS session in your environment should be revocable inside 60 seconds and revalidated against behavioral signals (geolocation jumps, impossible travel, device fingerprint changes, anomalous Graph API calls) at every privileged action. The specific implementation: enforce token binding where supported (Microsoft’s Continuous Access Evaluation, Google’s session control policies), set short token lifetimes on high-value applications (one hour or less for admin scopes), and route all OAuth grant approvals through a security review queue rather than self-service. Add Graph API audit log monitoring with alerts on first-time GraphRunner-pattern enumeration calls.
Against AI-Accelerated Vulnerability Discovery and Exploitation
- Shrink the patch deployment window for internet-facing systems to under 72 hours and pre-stage rollback for everything else. The current operating assumption in most enterprise patching programs (30 days for critical, 90 days for high) was built for a world where zero-day discovery was rate-limited by human researcher attention. That rate limit is dissolving. The defensive answer is not to chase every CVE faster; it is to harden the patch pipeline so that when a critical vulnerability is announced in software you run, it deploys to production in hours, not weeks. The implementation pattern: maintain a current asset inventory of internet-exposed systems mapped to exact software versions, automate patch deployment with canary stages, pre-test rollback paths quarterly, and establish a standing emergency change window with pre-approved scope. The goal is not to patch faster than the attacker discovers the bug; it is to be patched before they have time to weaponize it.
- Run continuous external attack surface monitoring against the same primitives an AI agent would target. Mythos and its successors look for the same things skilled humans look for, faster: forgotten dev environments, expired certificates, unpatched edge appliances, exposed admin panels, leaked credentials in code repositories, misconfigured cloud storage. A defender running a continuous external attack surface management (EASM) program against their own perimeter sees these exposures on the same time horizon an AI-augmented attacker would. The implementation pattern: weekly authenticated scans across all known external assets, daily passive enumeration for new assets, automated correlation against credential leak feeds and stealer log corpora, integration with your IDP to revoke credentials that appear in dumps within minutes rather than days. Treat the gap between exposure appearance and remediation as a measured SLO, not an operational nice-to-have.
- Reduce mean time to containment by re-architecting the SOC around minutes-not-hours response. When the attacker is an autonomous agent operating on its own decision loop, the dwell time math changes. A human attacker pausing to plan a lateral move buys defenders hours. An agent does not pause. Mean time to containment is the binding defensive variable in an agentic-attack world, and the way to compress it is to pre-author response actions and grant the SOC authority to execute them without escalation. The implementation pattern: maintain a documented playbook of containment actions (disable account, isolate endpoint, revoke session, block egress IP, kill EDR-detected process) executable by tier-1 analysts on detection without management approval. Tabletop these against agentic scenarios specifically, not just human-attacker scenarios. The single highest-leverage investment is reducing the time between “detection fires” and “containment action executed” from hours to minutes. Most enterprise SOCs measure mean time to detection but not mean time to containment; flip that priority.
These recommendations share a common shape: they are operational changes to existing capabilities rather than new tools to buy. The defensive technology stack most enterprises have today is largely adequate against AI-augmented attackers if it is operated at the speed those attackers will operate. The gap that opens over the next 6-18 months is not a tooling gap; it is a tempo gap. CISOs who close that tempo gap before the open-source Mythos arrives will be defending from a different starting position than CISOs who wait.
AI-Augmented Attackers Move in Minutes. Does Your Defense?
Flare delivers cyber threat intelligence, credential leak detection, and stealer log correlation: surfaced before they can be weaponized.
Background: How AI Models are Built
For readers unfamiliar with AI development, the following primer explains the key concepts referenced throughout this article.
First we can classify models into two types:
- Proprietary Models: These are frontier models developed by AI labs such as Anthropic, OpenAI, and Google. The weights of these models are not public. Frontier model providers use a defense in depth strategy to prevent the models being used maliciously to include refusals, blocking malicious requests, and banning accounts.
- Open-Weight/Open-Source Models: These models have their weights publicly available, leaving them open to a process known as abliteration, which removes all safeguards and refusals from the model. There is currently no known process to reliably prevent malicious output from an open-weight model.
All state of the art models to include Anthropic Mythos are currently proprietary models. There are five primary concepts to understand how AI is built and run:
- Pretraining: The model is trained on a vast corpus of human and synthetic data with the goal of “predicting the next token.” This phase is incredibly costly and compute intensive. For example, Google likely trained Gemma 3 (an open-weight model) on 2.3 × 10²⁴ FLOPs of compute for an estimated cost of $7-$10M.
- Reinforcement Learning: After pretraining, the model is refined through reinforcement learning, where it learns from feedback signals rather than raw text prediction. This includes RLHF (reinforcement learning from human feedback), where human raters compare model outputs and the model is tuned toward preferred responses, and increasingly RLVR (reinforcement learning with verifiable rewards), where the model is rewarded for getting math problems, coding challenges, or other ground-truth tasks correct. RL is where reasoning capabilities emerge: it teaches the model to think through problems step by step before answering. DeepSeek R1-Zero, for example, went from 10% to 71% on AIME 2024 over the course of RL training alone, using roughly one fifth of the base model’s pretraining computer.
- Fine-Tuning: Fine tuning adapts a general-purpose model to a specific task, domain, or behavior using a smaller, curated dataset. This can include supervised fine tuning on labeled examples, instruction tuning to make the model follow directions reliably, or domain adaptation to specialize the model for fields like medicine, law, or cybersecurity. Fine-tuning is dramatically cheaper than pretraining (orders of magnitude less compute) and is how most organizations customize frontier models for their own use cases without training from scratch.
- Inference: The model actually running: taking a user prompt and generating a response. Each token of output requires a full forward pass through the model, which is why output tokens are typically priced higher than input tokens by API providers. At scale, inference is where most of the lifetime cost of a model lives. A single frontier model serving millions of users will burn through far more compute on inference over its deployment than it consumed during pretraining.
- Scaffolding: The layer of tools, prompts, memory, and orchestration wrapped around the raw model to turn it into something useful. The same base model becomes a coding agent, a research assistant, or an autonomous penetration tester depending on what scaffolding it sits inside. This includes tool use (giving the model access to a browser, code execution, or APIs), retrieval augmented generation (pulling in relevant documents at query time), agentic harnesses (loops that let the model plan, act, observe results, and revise), and context engineering (managing what information the model sees at each step). Scaffolding is increasingly where real capability gains come from without additional training compute. Mythos Preview found zero-day vulnerabilities inside an agentic scaffold that ran the model in a loop with Claude Code, file access, and a debugger, with the model deciding for itself what to investigate next. The capability ceiling of a frontier model is set by training, but the capability floor in any given deployment is set by the scaffolding around it.
Model performance in a given domain can be improved through enhancing any of these variables. Between 2022 and 2025 most model improvements came from increasing the size of pretrained models exponentially. 2025 and 2026 saw significant gains from increasing reinforcement learning through a process known as reinforcement learning with verifiable feedback (RLVF) with the introduction of the OpenAI O1 series of models and increasing the amount of inference (time to think) models were given. Late 2025 also saw the introduction of agentic coding scaffolds with Anthropic’s Claude Code and OpenAI’s Codex.