Welcome to part two of our three-part blog series. In part one we discussed why we believe that using artificial intelligence for clustering malicious actors could help organizations in monitoring the dark web more effectively.
In the second installment of this Artificial Intelligence (AI) series, we will delve deeper into Natural Language Processing (NLP), a branch of AI. More specifically, we will demonstrate how it’s possible to cluster malicious actors based on the content they posted on various discussion forums. We will go over some key concepts of NLP, and provide you with some insight as to how we can use these tools and tailor them to the behavior of malicious actors. Before anything else, we need to collect some intelligence about malicious actors.
Gathering Information
For this first step, we used Flare’s database, which contains multiple years of information about more than two million malicious actors from all kinds of underground forums. This database is continuously updated and the number of malicious actors is constantly growing.
Looking at each actor featured in our database, we can observe a plethora of different things, including the actor’s activity on every monitored forum in which they participate. More intelligence is available, such as the actor’s PGP key, their registration date, their title, and various other information that can be used in other ways to profile malicious actors. In the scope of this project, however, what interests us is the title and content of the malicious actors’ forum discussion topics. Once enough data has been gathered, the next step will be to cluster the actors based on the content of their posts, for which we use NLP toolings.
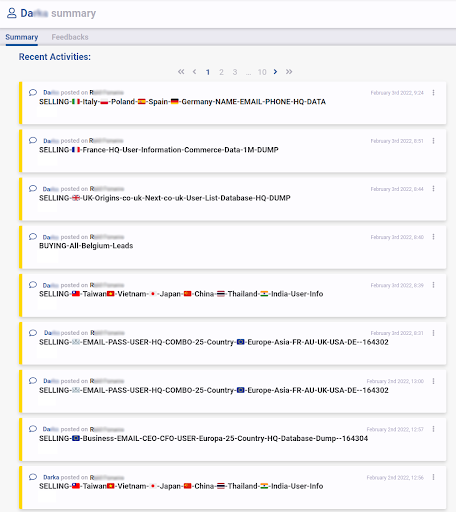
Figure 1 – The posting history of a malicious actor encountered on an illicit forum
Natural Language Processing
As previously mentioned, Natural Language Processing is a field of artificial intelligence; NLP’s purpose is to make a computer “understand” human language. It is used in numerous applications such as spam detection, translation, sentiment analysis, etc. NLP still is an active research area, thus many challenges are still unresolved. The truth is, humans have unique capabilities when it comes to interpreting nuances and different writing styles, capabilities that computers do not have.
Luckily, the last couple of years brought a great deal of advancements with the rise of Deep Learning: a different branch of Artificial Intelligence that attempts to emulate the human brain. Deep Learning makes it possible to feed an Artificial Intelligence system with text and have it “learn” the meaning of each word.
Unfortunately, most of the available tools rely on a pre-defined vocabulary, often based on well-written content such as news articles or the famous Wikipedia encyclopedia. This means these tools are not exactly adapted to the vocabulary used in underground forums, of which a great portion can be considered jargon and fraud-related lingo. Malicious actors not only have their own way of communicating, but are also located all around the globe and don’t limit themselves to the use of the English language alone. This brings us to our next challenge, building a vocabulary specific to the one used on underground illicit forums.
Building A Vocabulary
With underground communities continuously growing all around the world, as previously mentioned, these underground communities do not conform to a single language. The most spoken languages on these platforms are without a doubt English and Russian, but we also have encountered forums exchanging in a multitude of other languages, such as Polish, French, Vietnamese, to name a few.
Taking this into account, our first challenge was to compose a language tailored to these communities in order to train our artificial intelligence. This challenge can be further broken down into two aspects; we don’t want our vocabulary to be too large, as this will hinder the model’s learning process, and we don’t want it to be too small since there wouldn’t be enough information to learn from.
The first step in order to build our vocabulary is to generate a text corpus representing the underground wording. In order to do this, we use the textual data we have from each actor in Flare’s database. Consequently, this text corpus contains years of malicious actors’ publications on various underground forums.
The second step is to determine which words will be part of our vocabulary, and in order to do so, we need to tokenize our corpus. Tokenization refers to the concept of separating text into a series of words and subwords, known as tokens, and associating a unique identifier to each of these. This action is essential for every NLP application, as even if the model’s input is simply text, we need to transform it in order to create a representation that the computer will understand since as previously mentioned, computers don’t understand language as we do.
Whilst tokenization is not in the scope of this article, it’s important to note that there are several ways to tokenize textual content. With this in mind, Flare’s AI team developed their tokenization method to interpret text originating from underground vocabularies.
This method used the Byte-Pair Encoding (BPE) algorithm in order to identify words and subwords in the malicious actors’ text corpus. In this context, uncommon words are decomposed into subwords in order to reduce the vocabulary size, whilst frequent words are kept intact. Under these conditions, words like hacking and cracking are kept intact, while words like webcam are separated as two tokens, web and cam.
As another example, with Flare’s tokenization process, a sentence containing “Scam-Official-Request” will result in three main tokens [Scam, Official, Request] and will be classified as similar to another sentence containing these three words, but without the hyphens. Simpler techniques would not be able to separate this hyphenated sentence efficiently, as they might assume they are part of the same word.
The vocabulary used by malicious communities is constantly evolving, for example, NFTs are the talk of the hour whereas they never were mentioned a year ago. Hence why the algorithm is computed daily on a fresh text corpus in order to capture new trends in malicious actors’ discussions.
The following figure shows a subset of this vocabulary, represented in a two-dimensional (2D) space with a t-Distributed Stochastic Neighbor Embedding (TSNE) algorithm, which helps in visualizing high density data, something that would otherwise not be possible to represent in two dimensions. Each point in the representation is an approximation based on the understanding of the Artificial Intelligence for every word in the vocabulary. Therefore, we can see that some words with similar meanings, such as “hack” and “crack” are situated close to each other, the same goes for “Fullz” and “Carding”.
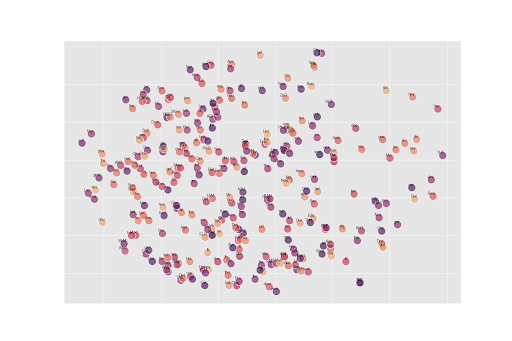
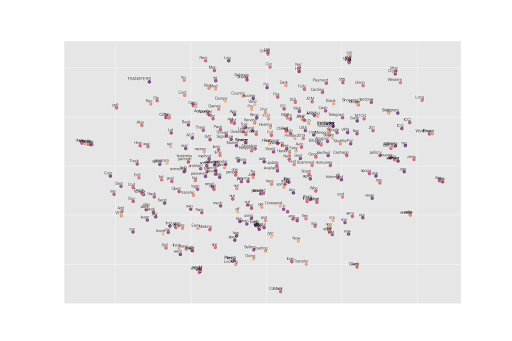
Figure 2 – a subset of the vocabulary used on illicit forums, clustered in a 2D space
With our vocabulary defined, and our Artificial Intelligence learning a representation from it, now officially comes the time to cluster similar actors based on the content of their posts.
Clustering Actors
The final component of this experiment was to position each actor into a spatial dimension. In other words, our AI model will “read” every actor’s publications, and will distribute them according to the content they are writing about as well as their writing style.
As new actors appear each day, every actor’s position is updated each day based on the new information we have, as mentioned above. In the following figure, we can represent a small subset of malicious actors using a TSNE algorithm, as we did for the vocabulary.
Figure 3 – a subset of actors encountered on illicit forums, clustered in a 2D space
(note: only the first two characters of the usernames are visible)
This concludes Part 2, giving you hopefully a better view and understanding of the various Artificial Intelligence technologies used in the development of Firework features. Don’t miss out on Part 3, the series finale, where we will go over how this technology brings valuable new intelligence to Firework. Subscribe to our newsletter to be among the first to receive future reports, delivered straight to your inbox!