The dark web is challenging to monitor. On top of it being structurally difficult to navigate, malicious actors have a unique vocabulary that is complex to understand for outsiders.
Web scraping and web crawling enable extracting and indexing information on a larger scale. These tools need manually written rules to function. Since these processes require human operators to write and maintain the web scraping configurations, it limits the amount of websites that can be monitored.
To automatically, and thus more efficiently, monitor the dark web, applying Natural Language Processing (NLP) to cyber threat intelligence can be effective.
With NLP, Flare has been able to:
- Analyze interactions between threat actors with the first tokenizer adapted to the dark web, the Dark Web Tokenizer
- Automate the web scraping process with the auto extractor, Kyber, which is able to extract the titles, publication date, and authors of a variety of illicit forums, without the need of human assistance
- Group malicious actors together to better understand threat risks with the Similar Actor Model
Flare has been monitoring the dark web since 2017, and as of early 2022, has logged almost 3 unique forum profiles, more than 1.6 million forum discussion topics, and nearly 1.9 million dark web listings!
Our AI Expert Olivier Michaud and Data/AI Lead Francois Masson spoke about Tokenizing the Dark Web: Applying NLP in the Context of Cyber Threat Intelligence at SecTor. Did you miss the talk? Don’t worry, we’ll discuss their presentation below.
What is Natural Language Processing (NLP)?
NLP is a field of Artificial Intelligence (AI) that concerns computers “understanding” human language. Various technologies combine so that computers can take in text or voice data and output a response that reflects the original writer’s/speaker’s intentions. Its practical applications include spam detection, translation, and sentiment analysis. There are many questions left to explore as it is an active research area.
Humans have unique capabilities for interpreting nuances and different writing/speaking styles, which is complicated to teach computers to accurately determine.
What is the Challenge of Analyzing Information from Illicit Sources?
There are too many data points and sources for a cybersecurity team to monitor all illicit content well.
There are several reasons why the dark web takes effort to navigate and analyze:
- It is fast-moving and has its own unique culture
- The most spoken languages are English and Russian by far, but there are other languages including French, Polish, and Vietnamese, so the analysis must be multilingual
- There’s jargon and fraud-related lingo
- There’s misspelled words and emojis
- Malicious actors have unique usernames (our perspective is that the tool should not learn every single username, but rather that a username is composed of letters, numbers, etc)
- In some situations, the writing style is important, so cleaning up text could result in losing relevant information (for example, one actor might be using question marks more than others)
How can NLP be Applied to the Dark Web?
Available NLP tools mostly monitor content from Wikipedia and are built around understanding “clean” English without jargon, misspelled words, and symbols/emojis. There are tools written by people to analyze information from illicit sources, but they are not automatic. Also, there’s not much research in this area because data coming from the dark web is rare.
Flare has been monitoring and documenting the dark web since 2017, and our AI team builds tools to analyze the growing number of threat actors and their activities on the platform.
Flare’s AI Expert Olivier Michaud collaborated with Flare for his masters thesis project in AI at the École de technologie supérieure. His research project investigated automating data extraction from various dark web forums using NLP, and Flare’s Kyber and Similar Actor Model tools stem from his ideas.
How to Speak “Malicious Actor”
Training a model using Natural Language Processing (NLP) is challenging. Training one adapted to the unique vocabulary of malicious actors becomes even more difficult.
There a few steps to accomplish to train a computer to understand the language of malicious actors:
1. Creating a New Lexicon
The typical native 20 year old English speaker knows about 40,000 words, and actively uses 20,000 of them. There are thousands more words that exist, not including misspelled words, word variations, and slang.
We didn’t want our vocabulary to be too large, because the model can’t learn every word, but it can’t be too small, since there won’t be enough information to learn from. Striking a balance between these enables the model to learn enough words to analyze them effectively.
2. Building the Tokenizer
Applying NLP involves transforming sentences into smaller units called tokens, which can be represented as text or numbers, and feeds the model. This process is tokenization.
There are many ways to tokenize, but here we chose the byte-pair encoding (BPE) algorithm. With BPE, uncommon words are split into subwords to reduce the vocabulary size, while common words are kept intact. So, the word “hacking” can be split into “hack” and “ing.”
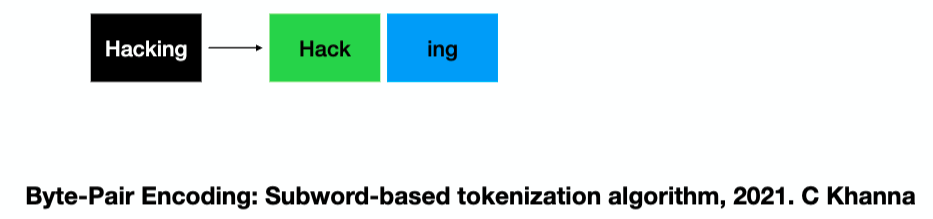
Sennrich, R., Haddow, B. & Birch, A. (2016). Neural Machine Translation of Rare Words with Subword Units. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1 : Long Papers), pp. 1715–1725. doi : 10.18653/v1/P16-1162.
This tokenizer has been trained by the Flare AI team text coming from 29 illicit sources in different languages over the course of several years, with several vocabulary sizes: 5,000; 10,000; 50,000; and 100,000.
As the vocabulary size increases, the number of tokens decreases. At 5,000 words, the tokenizer splits most of the words into subwords, while at 100,000 words, the tokenizer keeps most words intact.
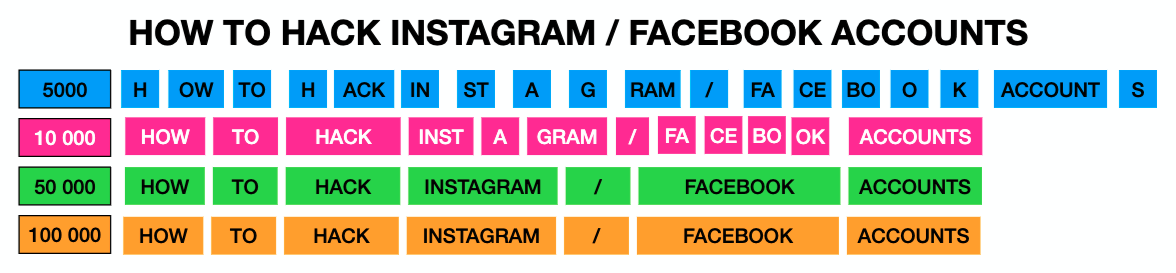
This is the first open-source tokenizer trained with a database containing years of content from interactions on the dark web. This tokenizer is available on GitHub.
Automatic Extraction of Content from Illicit Forums
Monitoring and extracting data from illicit sources (also known as web scraping) previously required creating manually written HTML/CSS rules for each webpage. Some challenges include:
- Websites are constantly evolving, so tools built to scrape them have to change too
- Forums have different style and HTML structures, so a rule that works for one may not for another
- There’s no available public data set
- Threat actors’ chatter can be confusing
With sequence labeling, cyber teams can scrape webpages proactively by teaching the tool certain word associations. For example, in this sentence about Star Wars, some of the words have associated categories.

With the auto extractor tool Kyber, the trained model can read HTML pages and output structured data. Kyber can:
- Adapt to webpage HTML changes over time: Websites are constantly evolving, and manually written HTML/CSS rules work when their code matches the webpage’s code, while Kyber is more flexible.
- Work on multiple sources: Kyber monitors a variety of illicit communities.
- Function without human intervention: Kyber is the first tool to automatically analyze dark web interactions, while other existing tools require manually written rules.
- Perform well: After analyzing 10 titles of dark web webpages with both the old method of manually writing HTML/CSS code for each page, Kyber was 90% accurate in detecting titles.

Another NLP Application to the Dark Web: Similar Actor Model
Kyber is not the only NLP-based tool that analyzes the dark web. The Similar Actor Model also applies NLP to illicit sources and relies on the tokenizer, which can have multiple applications.
This tool identifies similarities between threat actors so we can group similar actors by the content they posted.
The benefits of identifying similar actors include:
- Detecting a username change for a threat actor
- Identifying potential threats before any malicious action
- Providing valuable information in figuring out the risk a certain actor could pose to your organization
- Reducing noise encountered in investigations by determining low-risk dark web threat actors
Similar actors write similar content either because it’s the same person with a different pseudonym, or it is multiple actors working for the same organization or for the same interests.
Read more details about why, how, and the results of clustering malicious actors with AI with our report, Clustering Malicious Actors: A Three Part Artificial Intelligence Story.
What’s the Future of this Tool?
There are many possibilities for the auto extractor. Currently, it is limited to extracting information from forum topic pages.
Expanding the functionality of this tool in the future looks like applying its current capabilities to extract relevant information like secrets, API keys, entities, relationships between keys and entities, and more.
Also, instant messaging platforms like Telegram are becoming more popular for threat actors. Monitoring these with the Similar Actor Model would be helpful for cybersecurity teams.
And through monitoring instant messaging platforms, a possibility for this tool would be to make links between different communities. For example, it could track a threat actor who is an admin of a dark web forum, who then promotes it on a messaging group chat. This could also be layered with geographic information to study the relationships between actors located physically close to each other.
How Flare Can Help
Monitoring the dark web doesn’t have to be overwhelming. Flare enables you to automatically scan the clear and dark web for your organization’s leaked data, whether it be technical data, source code, leaked credentials, or secrets on public GitHub repos. This approach enables you to proactively identify sensitive data leaks and prevent data breaches before malicious actors utilize them.
Flare allows you and your security team to:
- Get ahead of reacting to attempted network intrusions before they happen by rapidly detecting stolen credentials and infected devices for sale
- Cut incident response time by up to 95% and monitor around 10 billion leaked credentials
- Understand your organization’s external data exposure (digital footprint) with proactive recommendations to improve your security posture based on real world, contextualized data
Want to see how Flare can monitor illicit sources for your organization? Book a demo for more information.